“Technical Debt” can sometimes be a slippery term in the software industry. If you talk about it long enough, it usually becomes apparent that the participants in the conversation have very different things in mind when they are referring to “tech debt” which impedes having a productive discussion about how to deal with it.
In essence, Tech Debt has become an umbrella term for “things in the code which make feature delivery slower or detract from delivered quality.” While this is still a useful categorization, it doesn’t lend itself well to being addressed proactively because it spans everything from naming issues that might take seconds to fix, up to major refactors which might take months to complete.
Thus when programmers and Project Managers talk about this, we often end up these sorts of conversations (with deep apologies to strawmen everywhere):
PM: “Just create a backlog item for any tech debt work you want to do and we’ll prioritize it!”
Dev: “We can’t create a backlog item every time we want to write a test or rename something, that’s insane!”
Or:
Dev: “We need to address some tech debt, it’s getting out of hand. These deadlines are killing us!”
PM: “Well we can’t just stop delivering features right now, it’s a really critical time for the business!”
Therefore, I think it is important to break down what we mean when we talk about tech debt. I would suggest breaking tech debt items into 4 general categories:
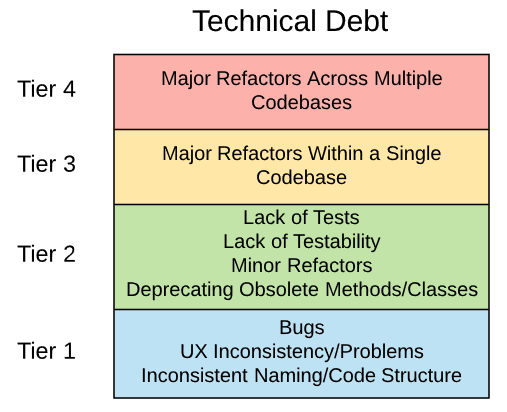
These are ranked from highest cost at the top, to lowest at the bottom. Let’s go through each of them to explore some examples:
Tier 1:
Bugs
Bugs refers to user-impacting regressions to existing or intended functionality. This would be things like error messages being displayed when a user submits a form, broken page layouts in certain browsers, or invalid data being displayed.
UX Inconsistency/Problems
UX issues refer to problems such as inconsistent navigation in a website, font that is too small to read, inconsistent use of UI elements across different pages, and other issues which may confuse the user but do not necessarily prevent valid use of the software.
Inconsistent Naming/Code Structure
These issues are very minor code issues. While they may seem pedantic at first brush, they can still impact productivity in subtle yet important ways. While troubleshooting a bug, a dev might search for a class by name, get no results, and be forced to spend 5-10 minutes searching for it by other means, due to its name being misspelled, or otherwise inconsistent with the rest of the codebase.
Given that most IDEs can update the name of a symbol across the whole codebase in seconds, it is a shame to lose minutes to something which could have been fixed in seconds if we had addressed it proactively.
Another example might be the use of properties instead of fields for class members, which can trip up certain serialization libraries, causing subtle bugs which may send developers unfamiliar with them on a wild goose chase.
Tier 2:
Lack of Tests
This refers to a codebase which has insufficient automated test coverage. The type of tests may vary, but tests lend a lot to the maintainability of a project by automatically ensuring that logic covered by tests can be modified without resulting in bugs. In Legacy codebases, or codebases which have undergone deadline-driven growth where features outstripped the tests, effort spent remediating this deficiency can be very valuable to the long-term success of the codebase.
Lack of Testability
Subtly different from a lack of tests - a lack of testability refers to code which is structured such that testing it is very difficult. Dependency on static classes, nondeterministic behavior, dependency on concrete types rather than abstractions, and high cyclomatic complexity all contribute to code that is difficult to write tests for.
The solution is to change the structure of the code such that it becomes testable. This can usually be done in small, incremental changes, each of which renders a little bit more code subject to test coverage.
Minor Refactors
This category refers to small refactors which can be done without huge investment. One example might be a class that may have started out well-factored but has slowly grown and is now 800 lines or more and has become a candidate for being split into multiple classes. Another might be when a library you depend on has released a new version with useful bug fixes or features, but also contains breaking changes that necessitate slight changes to the way we consume it when we update to the latest version.
Deprecating Obsolete Methods/Classes
Sometimes as our understanding of a problem domain evolves, we discover that code we have written is no longer valid or useful. It may be replaced by new code that more accurately reflects our updated domain model, but references to the old logic may hang around and continue to be used simply out of inertia.
In the interest of eventually deprecating the old logic, it is a good practice to address this proactively, since the new code will continue to diverge from the behavior of the old code, and this may eventually result in bugs - potentially urgent ones if the obsolete code we depend on is not directly under our control, such as a third party API.
Tier 3:
This tier refers to large-scale refactors which are in a single codebase, and can generally be accomplished by a single team. An example might be swapping out your database from SQL to NoSQL to alleviate a performance bottleneck, or replacing your SOAP API with a REST API to take advantage of an HTTP cache used elsewhere in your organization.
These are large units of work that may take anywhere from days to months, depending on the size of your application. They often come up as a result of evolving understanding of the problem domain in which you are working, scaling up your application to larger user counts or datasets, or evolving best practices within your organization.
Tier 4:
This tier refers to large refactors which span multiple codebases and consequently may involve multiple teams. They may also require a carefully orchestrated roll-out process, such as updating two APIs to both consume a new database in synchrony, or updating an API before we update its consuming UI applications. One example might be changing your model of a Customer to allow multiple administrators, while your APIs and UIs have previously been built with the assumption that each Customer has only one administrator in a naive early version of the the system. These changes are broad in scope and may affect an entire organization.
These refactors share many of the traits of those in Tier 3, except that they are even larger in scope and, crucially, span multiple teams. This means that the process of planning and prioritizing them requires balancing the cost and benefit of the work against not just one team’s priorities, but those of many teams.
Why It Matters
This may all seem pedantic, but it’s actually critical to the success of both your software and your business. As we make decisions about product development strategies, they can have both short term and long term consequences. By avoiding excessive technical debt, we allow ourselves to continue to make rapid changes to a quality product in the long term. Yet every Project Manager also knows that deadlines get features shipped. So how do we square these two concerns?
In short, it is an optimization problem. The speed at which we can deliver features is a function of the quality of the code itself. Clean code is easy to change and enhance, which means features get built faster. Yet there is often a “shortcut” path - getting the feature working “good enough for now” while leaving the code in a worse state than it was to begin with. So let us consider a few possible scenarios:
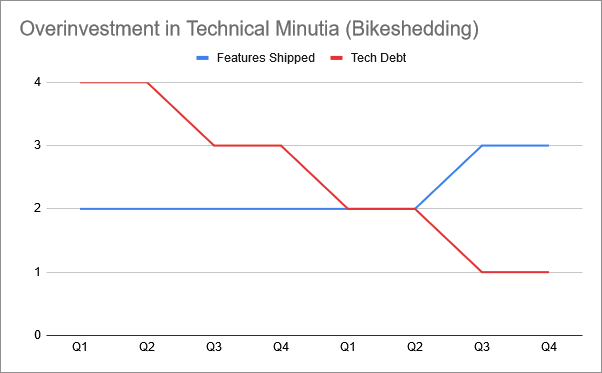
This is the scenario that Project Management fears - an over-optimization for code quality, where large technical investments are made without regard to how beneficial they are to the product. The ability to ship features more rapidly may eventually come, but does so slowly, and meanwhile the company’s competitors are shipping features and eating our market share. At the end of 2 years, we have shipped only 18 new features despite having had the development bandwidth to ship much more.
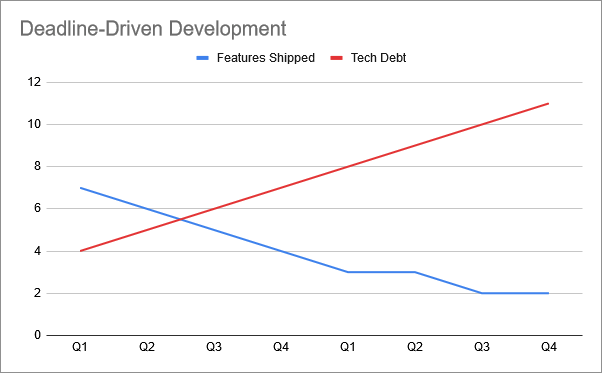
This is the scenario that developers fear - endless deadlines that try to wring features from a codebase that increasingly resembles spaghetti. We can get more features to market in the short term. But the development team is feeling the pain of neglected code - their feature work is slow, bug reports and customer complaints pile up, the performance metrics gradually get worse, and there’s that one server that just falls over from time to time and they have to step away from dinner with their family and log in at 9pm to prop it up again.
They know that this isn’t sustainable, it makes their job unrewarding, and by the end of the first year of this, feature delivery times are more than doubled. They are able to ship 32 features in 2 years, but the prospects of getting further features shipped is becoming increasingly dismal. The word “rewrite” starts to be thrown around.
While this approach may be warranted for startups, or businesses on the brink of extinction, it is not a good long-term strategy for an organization that expects to still be around in a few years.
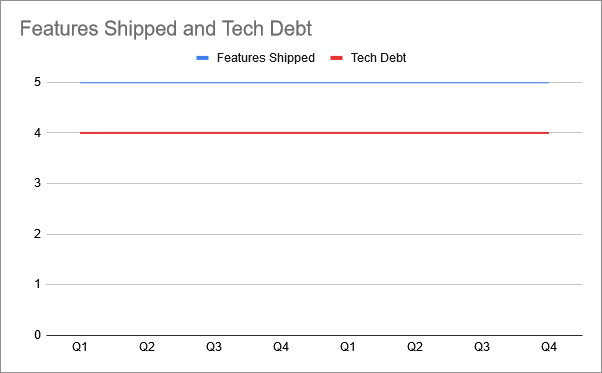
But what both parties would probably hope to achieve is something that looks a lot like this: the most onerous technical debt is remediated continually, and as a consequence of this technical investment, feature delivery can remain constant. While we will always have some technical debt, we do not allow it to become suffocating. And this allows us to continue shipping features as a consistently high rate for any number of years. In this model we are able to ship 40 features in 2 years, even more than the deadline-driven model - and without deteriorating our ability to ship future features in the process.
Of course such things are difficult to quantify, and the value of any given feature is itself a function of time - first to market gets the worm. So there will always be tradeoffs, but the fact that it is a difficult line to walk does not absolve us as technologists from the responsibility to try our best to maintain this balance.
So, how do we go about that?
An Optimal Solution
There are no silver bullets - the circumstances any given company and technology will vary. NASA’s requirements for code quality will be different from those of Facebook. So to some extent this will be an iterative process that your organization will have to go through, but based on my experience I can offer some guidelines for how to approach a solution that will work for you.
First, our approach for dealing with each type of tech debt will vary, but let’s look at an enhanced version of our chart from earlier:
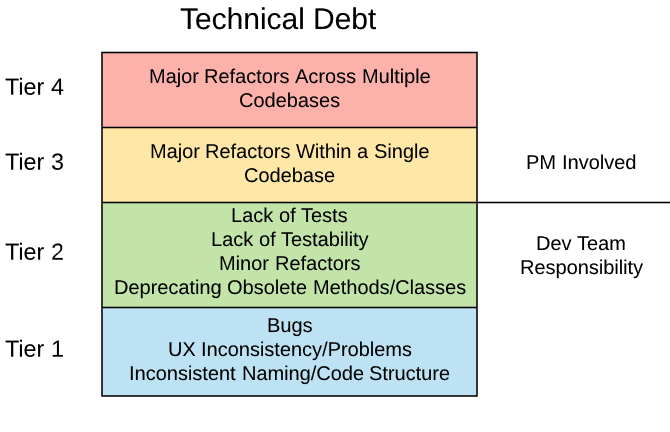
I propose that large refactors such as those in Tiers 3 and 4 are expensive enough that they deserve to be planned and prioritized alongside other backlog items, with the development team being the SMEs on both the technical effort and its value.
The value of technical remediation can be expressed in a variety of ways, but here are some factors to consider:
- Risk - reducing likelihood of a security breach or outage.
- Enabler - an architectural change which is a prerequisite to other features.
- Cost of Delay - does the tech debt incur some ongoing cost, such as licensing fees, affecting customer retention, or time spent remediating outages?
- Accelerator - while not a blocker on any product functionality, the change can accelerate the speed of future work for one or more teams.
Additionally, although tech debt in both Tier 3 and Tier 4 need to be addressed as backlog items, the strategy for doing so will be different since, by spanning multiple codebases, tech debt items in Tier 4 are likely to involve multiple teams, and require a specific rollout strategy for deploying them. This means that environmental factors can add to the technical complexity, and that multiple teams’ priority lists and bandwidth must be considered when planning the item.
Conversely, tech debt in Tiers 1 and 2 should be the responsibility of the dev team to proactively and continually address as part of their work process. But I am not suggesting that this should be a black box!
Indeed, I think that it is important for a dev team’s strategy for tackling these types of tech debt to be made clear to the organization.
Use Working Agreements to Your Advantage
A working agreement, whether verbal or written, is a statement from the development team about how they do work. It essentially supplies the answer to “how we do work” in answer to the backlog’s “what we work on.”
It may include things like a testing strategy, code/naming conventions, non-functional requirements, pull requests, or other techniques that allow code to be written and work to be prioritized in a manner consistent with the team’s objectives and philosophy.
Indeed, by carefully setting standards for how we do work, we can break the cycle of writing “good enough for now” code and then hoping to have time to fix it later. A common complaint dev teams is exactly this - that PM and management put pressure on them to deliver features that they can only accomplish by cutting corners.
Instead I would recommend flipping the script - as a development team you should make clear how work will be delivered by your team, and place the responsibility on PM to make a case that the development team should deviate from these practices in particular circumstances. In fact, this deviation can be a good thing if there is a significant threat to the business, or a time-sensitive market opportunity that necessitate a particular feature. But if your business plans to succeed long-term, it should be the exception and not the rule.
Below I offer some examples of working agreements oriented around handling or preventing tech debt that you may wish to consider:
Budgeting Time for Technical Investment
The team may decide that it wants to invest 20% of their time (1 day a week, perhaps) in tackling tech debt items from Tiers 1 and 2. This work will usually fit into a day or two, and by making the amount of time budgeted for such work explicit, it allows PM and the developers to negotiate together to determine what the right percentage might be. Perhaps 10% is right in your situation, or 40% - this will depend on your business situation and codebase.
Zero Bug Policy
This is a strategy for backlog prioritization in which bugs are prioritized first, above all other work. This can do wonders for your user experience, by ensuring that any bug a user encounters has a serious plan to be fixed, rather than languishing in a backlog, leaving their workflow broken for months or years.
Indeed, it is important to remember that any feature you have shipped in your product was, at one point in time, a dev team’s #1 priority - otherwise it wouldn’t have been worked on. In most cases, existing features your users depend on are just as valuable to your product as new ones, and ignoring bugs is effectively choosing a new feature over an existing one without actually realizing it.
Bug Budgets
Less drastic than a Zero Bug Policy, bug budgets are a more incremental approach to fixing bugs. A team may decide to fix, say, 2 bugs per iteration. Or budget 5 points of capacity especially for bugs. This allows feature work to still be prioritized despite an existing inventory of bugs, if you aren’t ready to take the leap to a Zero Bug Policy.
Team Within a Team
Sometimes you may have a single domain expert, senior dev, or general complainer who is especially interested in remediating technical debt. We discussed above the possibility of having each member of a team spend 1 day per week on technical items, constituting 20% of the team’s capacity. This is a different approach on the same concept - by allowing one developer in a team of 5 to address tech debt, you allocate 20% of your capacity to the work, and allow the person doing it to do so without the need for context switching between feature and technical work.
A team may also like taking turns doing this as a form of knowledge sharing (or burden-sharing, depending how bad your legacy code is!)
UX Mob Sessions/Demos
One way of addressing UI and UX issues in your product, rather than simply marking them all as “Bugs” and throwing them in your backlog, is to simply get many people in a room, from the dev team(s) to stakeholders, and just use the product. As you do this, everyone should be looking for things that are confusing, inconsistent, or slow. As feedback is given, simply make notes of the feedback you receive, and unless some of them are particularly difficult to fix, the dev team can commence working on them immediately after the mob session is done (or potentially even during it, depending on your technology.)
This can be a useful way of remediating UX issues, because with enough people in the room, (especially some untrained eyes) someone will spot most of them. And because UX problems are often very quick and easy to fix, the development session that emerges from this can yield rapid improvements to the UX in just a few hours.
Definition of Done/Non-functional Requirements
Lastly, this is a strategy for preventing tech debt from Tiers 1 and 2 from occurring during new work. Rather than waiting for performance issues to occur and then attempting to remediate them, we can include performance characteristics in a codebase’s Definition of Done (which overlaps with NFRs) for new work. If the page doesn’t load within 500ms, then you’re not done yet. This is a very useful tool for allowing forward progress on feature work without accruing technical debt that will impact customers, and which we will only have to pay back later.
Some characteristics you may wish to include in your definition of done:
- Code Coverage
- Adhering to UI/UX Best Practices
- Adhering to Naming/Style Conventions
- UI tests for important new UI features
- Performance characteristics, such as page load speed
- Validation of user inputs
- Pull request review by a dev
- QA review of the feature
Conclusion
I hope this article helped give you some ideas on how to discuss, categorize, and approach remediation of technical debt. While the conversation around technical debt is often framed as a clash between developers and PM, it is important to remember that at the end of the day, both groups are looking to ship as many high-quality features as possible.
By making the approach to handling tech debt items clear across all tiers of tech debt, you can initiate a dialog between dev and PM which allows you to iterate on your process and find the “Goldilocks” approach that is just right for your organization.
The only question that remains is how to do that in your circumstance, which is something your team will have to work together collaboratively to discover. I hope that the mental model I’ve shared in this article will prove useful to you in that endeavor!